Lezing uitgesproken bij de Avond voor Wetenschap & Maatschappij, Leiden, 7 oktober 2024
Wij zijn niet de enige communicerende diersoort, maar wij hebben wel een buitengewoon instrument ontwikkeld dat we menselijke taal noemen. De behoefte om te communiceren met klanken, gebaren en tekens combineren we met een voor dieren enorme honger naar informatie: we zijn, zou je kunnen zeggen, informavoren. We zijn voortdurend aan het rondsnuffelen naar lekkere hapjes informatie. Zoals uw lichaam zich voedt met wat er op uw bord ligt, voedt onze geest zich met informatie. Naast visuele informatie bestaat die hoofdzakelijk uit taal – tekst en spraak. De dag die achter u ligt zat ongetwijfeld vol met woorden. En dat geldt voor iedere dag daarvoor. En hoor mij nu. Tekst, spraak, taal, wat je ook doet, waar je ook bent. “Wat doet je moeder voor werk?” Vraagt een volwassene aan een kind. Het antwoord: “Typen!” En wat zijn wij in de wetenschap anders dan professioneel schrijvers? We leven met z’n allen een leven in taal. Dat is zo natuurlijk dat we er ons nauwelijks bewust van zijn. Taal is onze matrix.
Met dat beeld van de eindeloos en voortdurend talig communicerende, information foragers die we zijn, een term die begin jaren ’90 werd geformuleerd door onderzoekers van Xerox PARC, is het succes van internet en sociale media goed te verklaren. Er is iedere dag meer hapklare informatie dan ooit, en in plaats van dat we hem vroeger met een zaklamp moesten zoeken, in de bibliotheek, vindt de informatie ons inmiddels eerder dan dat wij ‘m zoeken. Ook het succes van de new kid on the block, ChatGPT, of generatieve AI in het algemeen, is goed te verklaren hieruit. Eerst een korte definitie van ChatGPT. In de basis bestaat ChatGPT uit één deel, GPT, dat teksten kan genereren, woord voor woord, die een plausibel vervolg zijn op het voorafgaande, bijvoorbeeld een vraag of een opdracht of een dialoog met de gebruiker. GPT genereert (de G), het is pre-trained, voorgetraind, op belachelijke hoeveelheden teksten (de P), en het draait op een specifieke kunstmatige neurale netwerkarchitectuur, de Transformer (de T – GPT). Ten tweede is ChatGPT een chatbot, een klets-robot. Het Chat-gedeelte vraagt het GPT-gedeelte om een heel aantal mogelijke vervolgen te genereren op wat er tot dusver aan tekst is gepasseerd, en kiest daar het, let op, meest hulpvaardige antwoord uit. Kortom, ChatGPT genereert plausibel klinkende, hulpvaardige teksten.

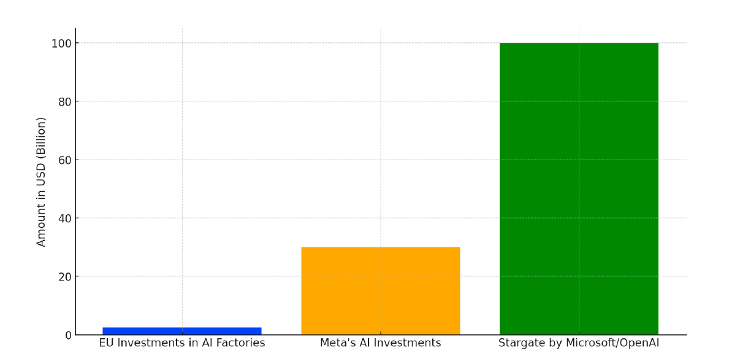
Bijvoorbeeld: Als ik ChatGPT vraag “Welke Nederlandse auteur had ook een nummer-1 hit?” dan komt ChatGPT met het antwoord “Jan Cremer, met de hit ‘Ich bin verliebt in die Liebe’”. Als ik vraag naar de tekst van het lied, dan krijg ik die. Leuk bedacht, absolute onzin, maar wel plausibel klinkend. De afgelopen bijna twee jaar hebben we kunnen wennen aan deze kletsmajoor die soms de mooiste teksten genereert maar die ook de raarste fouten maakt. Hier. Er zijn drie landen die in het Engels met de letter “Y” beginnen: Yemen, Zambia en Zimbabwe. ChatGPT genereert om de haverklap redeneerfouten en onwaarheden. Daarnaast herhaalt ChatGPT alle vooroordelen die ook in het trainingsmateriaal zitten, zoals op het vlak van genderongelijkheid. De tool kost belachelijk veel energie om te trainen, en het trainingsmateriaal is voor een groot deel opgebouwd uit teksten waarop copyright berust. Zomaar wat zware problemen met ChatGPT. Alle problemen kunnen in principe opgelost worden, maar de grote techbedrijven die deze tools ontwikkelen zijn niet bezig met het oplossen van die problemen; die zijn bezig met geld verdienen. En we weten dat de grote aantrekkelijke producten van de techbedrijven altijd harder lonken. Van onze eigen staten en de EU lijken we het in ieder geval niet te moeten hebben als het gaat om oplossingen, zoals deze grafiek in geplande investeringen in AI-fabrieken laat zien. De EU, Meta, en Microsoft/OpenAI. Hun Stargate, de grootste AI-fabriek ooit, kost 100 miljard dollar. Dat is net onder de Rijksbegroting van Nederland. Met collega’s Fabian Ferrari en José van Dijck zijn we de laatste jaren de governance-problematiek rond Generatieve AI in kaart aan het brengen. We zien lichtpunten in een groeiend besef in de EU van de noodzaak van reguleringen (en het uitdelen van boetes) en in investeringen, maar het lijkt allemaal wel te laat te komen. De grote tech bro’s van nu laten zich niet stoppen, wat wij vanuit de wetenschap ook doen om de hype te nuanceren. Het helpt niet, de media luistert naar AI-experts als Elon Musk en Yuval Harari. Die beweert in z’n nieuwe boek en in interviews dat LLMs geen tools zijn als alle technologie hiervoor, maar agents — het zijn juist geen agents! Ze kunnen niet redeneren, ze zijn niet zelfbewust, ze hebben geen standpunten. Ze voorspellen alleen maar het freaking volgende woord.
Grafiek (c) Fabian Ferrari.
Veel mensen vragen zich af: als dat het in de basis is, is ChatGPT dan een goed gelukte goocheltruc? Of is het meer dan dat, en kun je het ook zien als een wetenschappelijk interessant model van taal? (Disclaimer: ok begon 20 jaar geleden met een NWO Vici-project met deze vraag). We krijgen een duidelijk antwoord van taalkundige Noam Chomsky, 95 jaar oud en nog altijd actief, hier op een foto uit 1969 in zijn werkkamer bij MIT. Chomsky lanceerde van de jaren ’50 tot in deze eeuw toonaangevende modellen van taal, en zijn oordeel over ChatGPT is vernietigend. “Given the amorality, faux science and linguistic incompetence of these systems, we can only laugh or cry at their popularity”, schreef hij vorig jaar in de New York Times. Het wordt trouwens niet vaak opgemerkt, maar de naam van een van zijn eerste modellen van taal, Transformational Generative Grammar, overlapt opvallend met Generative Pre-trained Transformer. De twee taalgenerende machines, met 70 jaar tijd tussen hen in, verschillen als je goed kijkt alleen in hun grondstof: grammatica bij Chomsky, trainingsdata bij GPT.
En is ChatGPT echt zo slecht? Of moet de waardering genuanceerder zijn? Neem een Generatief AI-systeem dat we al wat langer kennen, Google Translate. Is gebaseerd op dezelfde technologie als ChatGPT, maar is ook door de relatief gefocuste vertaaltaak een stuk preciezer en betrouwbaarder gewordeneen. EngejseEngekse. Je ontkomt er niet aan om te denken dat ChatGPT en Google Translate toch iets begrepen moeten hebben van taal, als je dat zo antropomorfiserend mag zeggen. Of in mijn formulering: Google Translate en ChatGPT zijn door de computer gevonden oplossingen van vertalen en dialoog voeren. Die oplossing kan een hele andere zijn dan de oplossing van de mens, maar kan ons misschien toch iets over onze eigen oplossing en over taal vertellen.
Een mogelijke missing link in dit verhaal is wellicht het concept van het voorspellende brein, een idee dat op verschillende manieren door talloze onderzoekers, vooral neurowetenschappers, is geformuleerd en getest. Ik licht het werk van Karl Friston eruit (ja, weer een man, er komen er zo nog twee) en vat zijn idee kort door de bocht als volgt samen. Het brein is volgens Friston een voorspellende machine die erop is gebrand om zo min mogelijk verrast te worden. Het brein gebruikt daarvoor een model van de wereld, of bijvoorbeeld van taal, en genereert voortdurend voorspellingen van hoe de wereld (of taal) er op korte termijn uit gaat zien, op basis van zintuiglijke perceptie. Het brein vergelijkt de eigen voorspelling met wat de zintuigen zeggen, en slechts bij afwijkingen van de voorspellingen gaat het brein extra cognitieve moeite steken in het verklaren van de afwijkende input.
Een generatief groot taalmodel als GPT is ook een voorspellende machine, die met een model van taal in staat is om woord voor woord een plausibele nieuwe tekst te genereren. Een enigszins vergelijkbaar functioneel doel, maar nu alleen gebruikt voor taalproductie. Maar: grote taalmodellen kunnen ook in de luisterstand gezet worden. En vervolgens is het technisch goed mogelijk om de verrassing te meten in een large language model tussen de voorspelling van het model en het werkelijke volgende woord.
Ik heb het voorrecht gehad om samen te mogen werken met een groep psycholinguïsten en neurowetenschappers die taal in het brein bestuderen, in het Zwaartekrachtproject Language in Interaction. Ons gezamenlijke werk sluit aan bij dat van een nog veel grotere groep van wetenschappers die observaties hebben gedaan waarin een verband gelegd wordt tussen grote taalmodellen zoals GPT, en activiteit in het brein wanneer de input afwijkt van de verwachtingen.
Dit plaatje komt uit een studie van PhD-student Alessandro Lopopolo waarin proefpersonen in een MEG-scanner lagen te luisteren naar audioboeken. Verschillende AI-taalmodellen “lazen” dezelfde teksten. Op hetzelfde moment dat een AI-taalmodel vond dat er een onverwachte klank, een onverwacht woord, of een onverwachte woordsoort in de voorgelezen tekst opdook, lichtten tegelijk verschillende onderdelen van de cortex aan de linker- en rechterhersenhelften van de proefpersonen op. Dit generaliseerde over proefpersonen heen.
Inmiddels durft een groeiende groep taalkundigen en psycholinguïsten te beweren dat grote taalmodellen als GPT wel degelijk bruikbare instrumenten zijn om taal en communicatie te begrijpen. Dit kantelende denkproces heeft energie gegeven aan een ontstane breuk met een diepgeworteld idee, onder andere van Chomsky, over de relatie tussen taal en andere cognitieve vaardigheden als denken, zoals wordt verwoord in dit artikel van Fedorenko, Piantadosi en Gibson, in Nature, deze zomer. Language is primarily a tool for
communication rather than thought. Het taalnetwerk en andere hogere cognitieve taken, plannen, redeneren over de wereld en over de ander, zitten op andere plekken in het brein.
Alles is taal, en ChatGPT is een van de eerste tools in de kunstmatige intelligentie die vol op het taal-orgel gaat — met succes. Maar de tool is verre van de betrouwbare kunstmatige intelligentie die velen van ons er in zien. We hebben nog veel werk aan het waarschuwen voor de problemen, het werken aan oplossingen, zoals de integratie met veel preciezere en betrouwbaardere componenten die de AI in de afgelopen halve eeuw heeft opgeleverd, en, noodzakelijkerwijs, het afdwingen van regelgeving die de techbedrijven moet helpen te stoppen in hun waanzinnige wedloop naar steeds grotere modellen met steeds grotere problemen.
Ik sluit af met misschien wel de diepste waarschuwing, van wiskundige, logicus en filosoof Kurt Gödel. Albert Einstein zei dat zijn naoorlogse jaren bij Princeton, de nadagen van zijn carrière, kleur hadden omdat hij aan het eind van iedere werkdag met Gödel naar huis kon lopen. Hier zijn de twee mannen. Gödels waarschuwing luidt: “Er is een verschil tussen een ding en praten over een ding”. Het Nature-artikel dat ik net noemde versterkt die bewering eigenlijk alleen maar. Taal kan plausibel en overtuigend klinken, maar totaal niet kloppen met de wereld erachter. In de maatschappij, in de politiek, in de wetenschap. ChatGPT houdt ons een spiegel voor, en toont de overtuigende kracht van taal: door ons verbluffend goed na te doen, en tegelijk nog de stomste fouten te maken, laat het de kracht en de valkuil van plausibele taal zien. En dan doemt het volgende probleem op: wanneer zien we het verschil niet meer tussen teksten die door mensen of machines zijn gegenereerd? Of zien we dat nu al niet meer en zijn we al ruimschoots in de aap gelogeerd? Ook voor dit probleem bestaan overigens oplossingen, zoals watermarking en fingerprinting, maar dat is voor een andere keer. Ik sluit af. Niet alles is taal. Er is en blijft een verschil tussen een ding en praten over een ding.